Data architecture is essential for data scientists. It's the foundation on which data scientists build their models and insights. A well-designed data architecture can help data scientists to be more productive, efficient, and accurate.
In this blog post, I'm going to introduce you to the "million dollar slide" on data architecture. This slide is a simple diagram that shows the different components of a data architecture. It's so simple, but it's also incredibly powerful.
The Million Dollar Slide
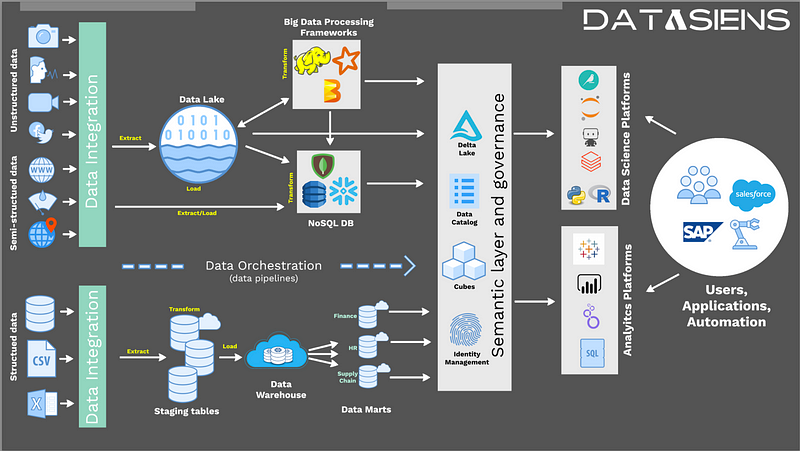
The million dollar slide is a diagram that shows the different components of a data architecture. It's divided into three main sections:
- Data Sources: This section shows the different types of data that an organization might have, including structured data, unstructured data, and semi-structured data.
- Data Pipelines: This section shows the different steps that data takes as it moves through an organization's data architecture, including processing through data warehouses and data lakes.
- Business Applications: This section shows how data is used in business applications to create insights and drive decision-making, often leveraging modern architectures like feature stores and streaming data architectures.
The million dollar slide is so powerful because it's a simple way to visualize the complex process of data architecture. It's also a great way to communicate with non-technical stakeholders about the importance of data architecture.
The Two Flows
The million dollar slide shows two different flows of data:
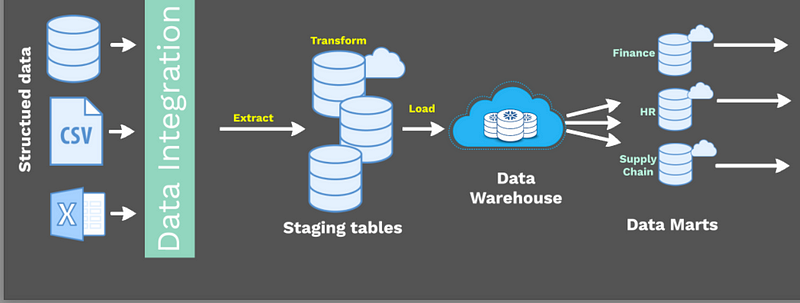
- The bottom flow: This flow shows a legacy data pipeline with a data warehouse and data mart.
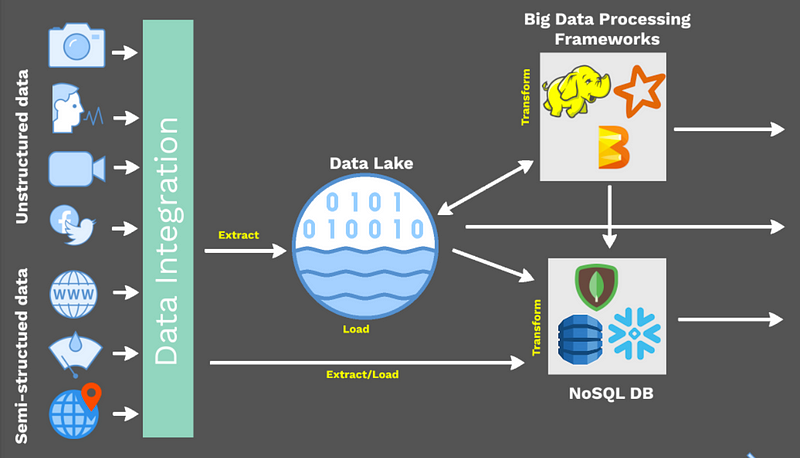
- The top flow: This flow shows a more modern data pipeline with a data lake.
The bottom flow is the traditional way of storing and managing data. It's a good solution for organizations that have a lot of structured data. However, it can be difficult to scale and it can be challenging to integrate with new data sources.
The top flow is a more modern way of storing and managing data. It's a good solution for organizations that have a lot of unstructured data or that need to be able to scale quickly. Modern approaches like data lakehouses and data fabric architectures are bridging the gap between these two approaches. However, it can be more complex to manage and it can be more difficult to find data.
In this blog post, we've just scratched the surface of the million dollar slide. In future posts, we'll explore the slide in more detail and we'll discuss how data scientists can use it to improve their work. We'll dive deep into topics like vector databases, data mesh architectures, and data contracts for ensuring data quality.
If you're interested in learning more about data architecture, I encourage you to enroll in my course on Udemy. The course covers all aspects of data architecture, including the million dollar slide.

Ready to dive deeper? Start with our comprehensive guide on structured data types to understand the foundation of modern data architectures.