In this blog post, I'm going to get you up to speed with streaming data and its profound impact on data science. We'll explore the significance of streaming data, its real-time applications across industries, and delve into key technologies like Apache Kafka. Additionally, we'll discuss the Lambda and Kappa architectures, which play a vital role in processing streaming data. So read on to discover the exciting world of streaming data!
Understanding Streaming Data: Streaming data refers to the continuous flow of real-time data from various sources such as sensors, weblogs, and online transactions. Unlike batch data processing, which occurs periodically, streaming data requires immediate or near-immediate processing. This characteristic enables organizations to gain actionable insights in real time and respond swiftly to dynamic events. Modern streaming architectures often integrate with data lakes for storage and feature stores for real-time feature serving.
Real-Time Use Cases

Real-time processing of streaming data has transformative applications in diverse domains. For example, in the finance sector, real-time data processing is crucial for detecting payment fraud. By continuously analyzing transaction data, anomalies can be identified in real time, preventing potential financial losses. Similarly, predictive maintenance in the manufacturing industry relies on streaming data from sensors to detect equipment failures and prevent costly downtime. Moreover, large retailers utilize streaming data to provide personalized product recommendations, enhancing the customer experience. These use cases often leverage vector databases for similarity search and feature stores for real-time feature retrieval.
The Power of Kafka

Apache Kafka, an open-source distributed streaming platform, plays a pivotal role in handling streaming data. Acting as a central nervous system, Kafka enables the efficient and reliable ingestion, storage, and processing of high-throughput data streams.
Producers, such as sensors or log files, write data into Kafka topics, which are distributed across multiple Kafka servers called brokers.
Consumers, on the other hand, read data from these topics for various purposes, such as real-time analytics, model training, or making predictions. This data often includes semi-structured data from IoT sensors and unstructured data from logs and events.
Kafka's scalability, fault tolerance, and support for parallel processing make it a popular choice for streaming data architectures. Organizations implementing data mesh architectures often use Kafka as the backbone for domain-to-domain data sharing while maintaining data contracts for quality assurance.
The Lambda Architecture

The Lambda architecture is a widely adopted approach for processing streaming data in real time. It combines batch and real-time processing to achieve both speed and accuracy. In this architecture, streaming data is ingested into a distributed streaming platform like Kafka. Simultaneously, data processing jobs continuously analyze the incoming data, leveraging frameworks like Apache Spark or Apache Flink. Processed data is then stored in a data lake house, which serves as a central repository for historical and real-time data. Deployed models can access this data for making predictions, enabling real-time insights and decision-making. The Lambda architecture provides fault tolerance, handles varying data velocities, and supports complex analytics scenarios. This approach often integrates with feature stores to serve real-time features for machine learning models.
The Kappa Architecture
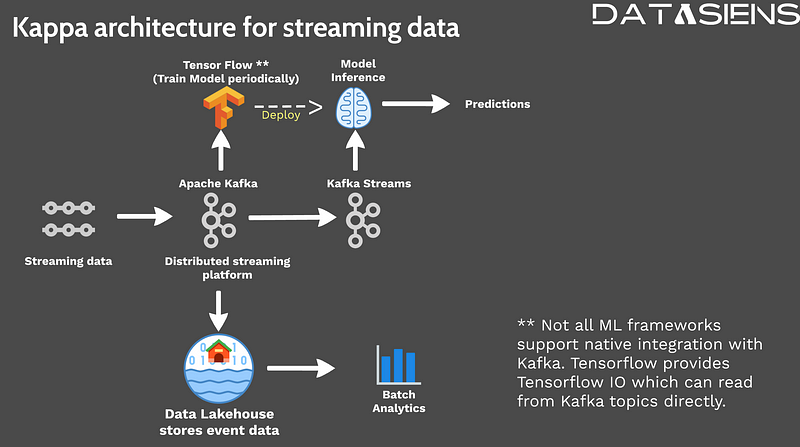
To overcome some limitations of the Lambda architecture, the Kappa architecture emerged as an alternative for processing streaming data. The Kappa architecture simplifies the data pipeline by eliminating the batch layer, focusing solely on real-time data processing. Data sources stream data directly into Kafka, where it is consumed by processing applications. Frameworks like TensorFlow can be integrated with Kafka to perform model training directly on streaming data. Processed data can be offloaded from Kafka to a data lake house for historical analysis or long-term trend discovery. The Kappa architecture offers simplicity, reduced latency, and streamlined data processing for real-time use cases. This architecture works particularly well with vector databases for real-time similarity search applications.
Comparing Lambda and Kappa Architectures
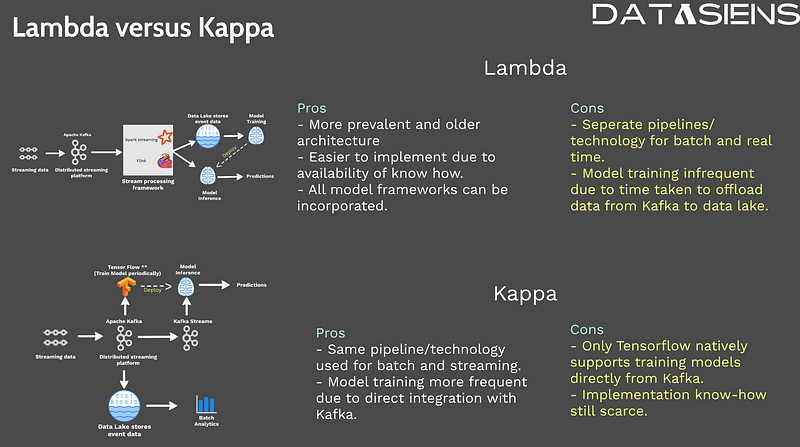
While the Lambda architecture has been prevalent due to its maturity and widespread support, the Kappa architecture provides an attractive alternative for certain use cases. The Lambda architecture's batch layer enables complex historical analysis, but it introduces additional latency in model training due to data transfer between Kafka and the data lake house. In contrast, the Kappa architecture offers reduced latency by directly processing streaming data within Kafka. However, it requires frameworks to support integration with Kafka, which might require additional development effort. Organizations must carefully consider their specific use case requirements and trade-offs when choosing between these architectures. Both approaches benefit from integration with feature stores for consistent feature serving across batch and streaming contexts.
Conclusion
Streaming data is revolutionizing the way organizations harness real-time insights. By understanding the concepts of streaming data, technologies like Apache Kafka, and the Lambda and Kappa architectures, data scientists can unlock the full potential of real-time analytics and decision-making. Whether you opt for the versatility of the Lambda architecture or the streamlined real-time processing of the Kappa architecture, leveraging streaming data opens up new possibilities for innovation and success in data science. As you implement streaming solutions, consider how they integrate with your broader data architecture, including data lakes, data warehouses, vector databases, and data mesh patterns to create a comprehensive, real-time data ecosystem.