In the rapidly evolving landscape of data-driven organizations, ensuring data quality and reliability has become paramount. As businesses increasingly rely on data for critical decision-making, the need for robust data governance mechanisms has never been more pressing. Enter data contracts — a revolutionary approach to data management that promises to transform how organizations handle data quality, lineage, and governance. Unlike traditional approaches that treat data quality as an afterthought, data contracts establish clear agreements between data producers and consumers, ensuring that data meets specified quality standards from the outset. This approach is particularly crucial when working with diverse data types, from structured data in traditional systems to unstructured data and semi-structured data in modern architectures.
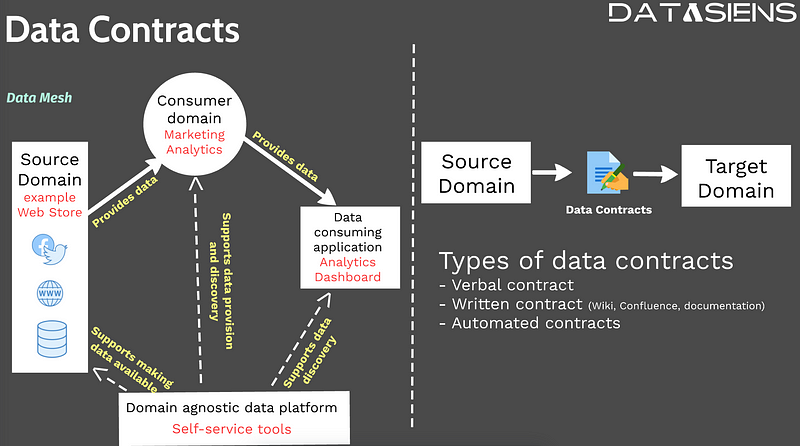
Data contracts serve as formal agreements between data producers and consumers, defining the structure, format, quality expectations, and semantic meaning of data. Think of them as APIs for data — they provide a clear interface that specifies what data will be delivered, in what format, and with what quality guarantees. This contractual approach ensures that downstream consumers can rely on the data they receive, reducing the risk of data quality issues and enabling more robust data pipelines. Data contracts are essential components in modern data architectures, whether you're working with traditional data warehouses, scalable data lakes, or next-generation data lakehouses.
One of the key benefits of data contracts is their ability to shift data quality concerns "left" in the development lifecycle. Instead of discovering data quality issues during analysis or model training, data contracts enable teams to catch and address these issues at the source. This proactive approach not only saves time and resources but also prevents the propagation of poor-quality data throughout the organization. When implemented in streaming data architectures, data contracts can provide real-time validation and quality assurance, ensuring that data quality is maintained even in high-velocity environments.
Data contracts also play a crucial role in enabling data mesh architectures, where domain teams take ownership of their data products. In a data mesh environment, data contracts serve as the interface between different domains, ensuring that data products meet the quality and format expectations of their consumers. This decentralized approach to data management requires robust governance mechanisms, and data contracts provide the foundation for maintaining data quality and consistency across domain boundaries.
The implementation of data contracts requires careful consideration of the underlying data infrastructure. Modern data platforms must support contract validation, monitoring, and enforcement capabilities. This includes integration with data catalogs, lineage tracking systems, and quality monitoring tools. Feature stores can particularly benefit from data contracts, as they ensure that features meet quality standards before being served to machine learning models. Similarly, vector databases can use data contracts to validate the quality and consistency of embeddings and vector representations.
As organizations continue to scale their data operations and adopt more sophisticated data architectures, data contracts will become increasingly important for maintaining data quality and governance. The integration of data contracts with emerging technologies such as artificial intelligence and machine learning will enable more robust and reliable data-driven applications. By establishing clear expectations and accountability for data quality, data contracts help organizations build trust in their data and make more confident decisions. Consider how data contracts can enhance your data architecture, whether you're working with traditional data warehouses, modern data lakes, innovative data lakehouses, real-time streaming architectures, or decentralized data mesh implementations.
Verbal, Written, and Automated Data Contracts
- Verbal contracts involve informal agreements on data creation and maintenance to prevent pipeline disruptions. However, their reliability is often questionable in today's fast-paced and complex data environments.
- Written contracts provide a more tangible solution by documenting the agreed-upon schema and data types. These documents, maintained on platforms like wiki pages or Confluence, offer clarity but lack enforceability.
- Automated contracts represent the optimal approach, acting as checks and balances that verify alignment with agreed-upon formats as data is created, written, and read. This automation prevents unplanned outages and ensures the integrity of data products.
An Example Data Contract in YAML
To better understand the practical application of data contracts, let's examine a sample data contract articulated in a YAML-like declarative syntax. This example focuses on validations for a dataset, specifically a timeseries dataset, ensuring its schema integrity and the reliability of its data.
checks for timeseries:
- schema:
- invalid_count(email) = 0:
valid format: email
- valid_count(email) > 0:
valid format: email
- failed rows:
samples limit: 50
fail condition: x >= 3
- correlation:
- avg_x_minus_y between -1 and 1:
avg_x_minus_y expression: AVG(x - y)
This YAML snippet outlines a series of validations:
-
Email Validation Checks: These checks ensure that all email addresses in the dataset conform to a standard email format. The
invalid_count(email) = 0validation ensures there are no email addresses that deviate from the valid format, whilevalid_count(email) > 0confirms the presence of at least one legitimate email address in the dataset. -
Failed Rows Check: This validation is designed to identify rows that meet or exceed a specific condition, in this case,
x >= 3, with a sample limit of 50 rows. This check helps in spotlighting potential outliers or anomalies within the dataset. -
Correlation Check: Focusing on the relationship between two variables, this validation ensures that the average difference between
xandy(avg_x_minus_y) remains within a range of -1 to 1. This is crucial for analyses that rely on the stability or consistency of these relationships over time.
By incorporating such validations into data contracts, organizations can safeguard against data quality issues and foster a more reliable data ecosystem.
The Future of Data Contracts
Looking ahead, advancements in technology might enable large language models to autonomously generate data contracts based on dataset observations. Enforcing these automated data contracts becomes a critical step in ensuring that data exchanged between domains complies with established formats and agreements.
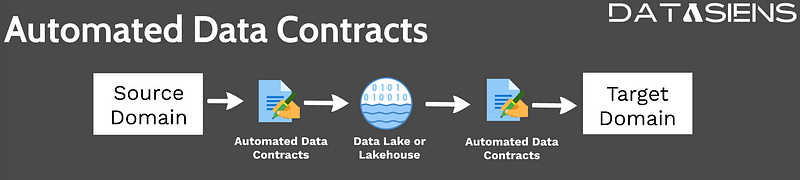
When a source domain contributes data to a data lake or lakehouse, it must pass through these automated validations to ensure compliance. Similarly, when the target domain retrieves data, it undergoes verification to guarantee alignment with pre-established agreements.
Conclusion
For data scientists, understanding and implementing data contracts within a data mesh framework is crucial for navigating the complexities of data management and ensuring the integrity and reliability of data products. As the field continues to evolve, embracing automated data contracts will be key to fostering seamless collaboration between domains and enhancing the overall quality of data ecosystems.