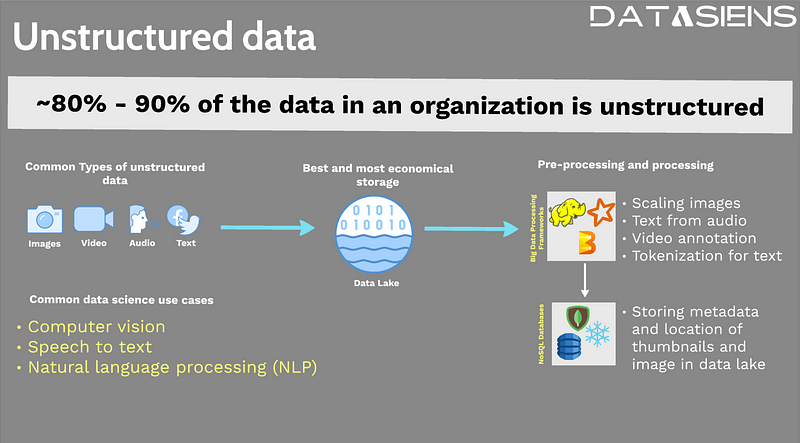
In the realm of data science, unstructured data presents a unique challenge and opportunity for organizations. Surprisingly, it accounts for a significant portion, approximately 80% to 90%, of an organization's data. While most of your projects may revolve around structured data, organizations are recognizing the value hidden within unstructured data and making remarkable progress in extracting insights from it.
Types of Unstructured Data
Unstructured data encompasses a range of formats, including images, videos, audio, and text. For instance, images can be captured by cameras on a factory assembly line or within a self-driving car. Audio files may result from recorded conversations, such as those held with a contact center for quality purposes. Text data is ubiquitous, found in product reviews, invoices, and social media conversations. Analyzing text data has become particularly valuable for organizations seeking actionable insights through vector databases and semantic search.
Data Science Use Cases utilizing Unstructured Data
Unstructured data opens doors to numerous data science use cases. For example, a mobile manufacturer might use computer vision techniques to detect cracks on device displays automatically. Speech-to-text or text-to-speech conversions are also common use cases. Additionally, analyzing the quality of conversations conducted by support agents requires transcribing them into text for further analysis. Natural language processing (NLP) is another emerging field, with applications ranging from intelligent chatbots that mimic human interactions to sentiment analysis of product reviews using vector embeddings and similarity search.
The Role of Data Lakes
As unstructured data represents a significant portion of an organization's data, it necessitates an economical and efficient storage solution. This is where the concept of a data lake comes into play. A data lake serves as a repository for storing vast amounts of unstructured data alongside semi-structured data.
Processing Unstructured Data
Before unstructured data can be effectively utilized for data science projects, it requires substantial processing. Due to the sheer volume of unstructured data, specialized processing frameworks have evolved to address this challenge. These frameworks enable tasks such as image scaling for machine learning algorithms, text extraction from audio files, and video annotation. Processing frameworks like Hadoop, Spark, and Apache Beam read data from the data lake, perform the necessary transformations, and write the results back to the data lake. For real-time processing needs, organizations often implement streaming data architectures to handle continuous data flows.
The Role of NoSQL Databases
NoSQL databases offer flexibility in handling various data models beyond traditional tables with rows and columns. While they can store unstructured data, it can become cost-prohibitive due to the need for expensive disk storage for performance reasons. Therefore, it is recommended to store unstructured data in a data lake and store the corresponding metadata in a NoSQL database. For example, the actual image can reside in the data lake, while a NoSQL database stores its location, thumbnail, and other properties. This approach allows for faster analysis of image properties while minimizing storage costs. Modern architectures like data lakehouses provide even better integration between storage and processing capabilities.
Conclusion
In this blog post, we have explored the world of unstructured data and its significance in data science. We discussed the types of unstructured data, including images, videos, audio, and text, and explored various data science use cases that leverage its potential. Additionally, we introduced the concept of a data lake as a storage solution for unstructured data and highlighted the role of processing frameworks and NoSQL databases in harnessing its power. Understanding the challenges and opportunities presented by unstructured data is essential for data scientists seeking to unlock valuable insights and drive innovation in their organizations. As you continue your data architecture journey, explore how vector databases, feature stores, and data mesh architectures can further enhance your unstructured data capabilities.