In the rapidly evolving landscape of machine learning and data science, feature stores have emerged as a critical component for managing and serving features at scale. As organizations increasingly rely on machine learning models to drive business decisions, the need for efficient feature management becomes paramount. Feature stores provide a centralized repository for storing, versioning, and serving features, enabling data scientists and machine learning engineers to streamline their workflows and improve model performance. Unlike traditional structured data storage in data warehouses or raw data in data lakes, feature stores specialize in pre-processed, ML-ready features.
Enhancing Efficiency with Feature Stores
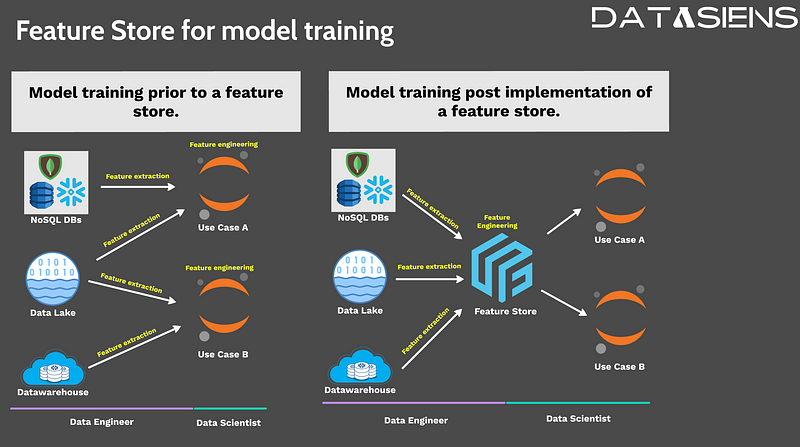
Traditionally, data scientists faced the arduous task of extracting and engineering features separately for each use case. This approach resulted in duplicated efforts and limited reusability of engineered features. Enter the feature store, a game-changer in the machine learning realm. A feature store centralizes feature extraction and engineering, freeing data scientists from repetitive tasks and reducing dependency on data engineering teams. With a feature store in place, data scientists can request the extraction and loading of features on a scheduled basis, empowering them to independently engineer new features. Moreover, feature stores promote collaboration among data scientists, enabling the reuse of engineered features and enhancing model accuracy while saving valuable time and effort.
The Role of Feature Stores in Inference

Inference, the phase where deployed models make predictions, plays a critical role in various machine learning applications. Let's consider a popular use case: payments fraud detection. When analyzing a transaction for fraud, relying solely on transactional information may lead to false positives or false negatives. To improve accuracy, models can benefit from additional features, such as customer engagement data, default location, known device mapping, or aggregated activity logs. Without a feature store, gathering and computing these features from diverse data sources in real-time would be impractical. Instead, a feature store enables the precomputation and storage of relevant features, ensuring that predictions can be made swiftly and accurately. With features readily available, the inference pipeline seamlessly combines transaction information with feature store data, facilitating real-time predictions.
Payments Fraud — Real time use case in banking
Payments fraud detection is a critical use case in the banking and finance domain, where accurate and timely classification of transactions as safe or fraudulent is paramount. When analyzing a transaction for fraud, relying solely on transactional information may lead to false positives or false negatives. To improve accuracy, models can benefit from additional features that provide contextual information. For instance, incorporating customer engagement data, default location, known device mapping, and aggregated activity logs can significantly enhance the fraud detection process.
Conclusion
The introduction of feature stores revolutionizes machine learning workflows by centralizing feature extraction and engineering, reducing redundancy, and fostering collaboration among data scientists. By leveraging a feature store, data scientists can accelerate the machine learning life cycle, improve model accuracy, and save valuable time and effort. Moreover, feature stores play a crucial role in real-time inference, ensuring swift and accurate predictions by precomputing and storing essential features. Embrace the power of feature stores and transform your machine learning endeavors into efficient and impactful processes.
If you're interested in learning more about data architecture, I encourage you to enroll in my course on Udemy. The course covers all aspects of data architecture, including an understanding of feature stores.
We'd love to hear about your experiences with feature stores. Have you implemented a feature store in your workflows? How has it impacted your machine learning projects? Share your insights and join the conversation in the comments below!
Feature stores address several key challenges in machine learning workflows. First, they provide a centralized location for storing and managing features, eliminating the need for data scientists to recreate features from scratch for each project. This not only saves time but also ensures consistency across different models and teams. Second, feature stores enable feature reusability, allowing data scientists to leverage existing features for new models and experiments. This promotes collaboration and knowledge sharing within the organization. Third, feature stores facilitate feature versioning and lineage tracking, ensuring that models can be reproduced and audited effectively. These capabilities are particularly important when integrating with streaming data architectures for real-time feature computation and with vector databases for embedding-based features.
Feature stores typically consist of two main components: the offline store and the online store. The offline store is designed for batch processing and model training, storing historical features that can be used for training machine learning models. This store is optimized for high-throughput reads and can handle large volumes of data efficiently. The online store, on the other hand, is designed for real-time inference, providing low-latency access to features during model serving. This dual architecture ensures that feature stores can support both training and inference workloads effectively. The offline store often integrates with data lakes and data lakehouses for scalable storage, while the online store may leverage vector databases for similarity-based feature retrieval.
One of the key benefits of feature stores is their ability to bridge the gap between data engineering and data science teams. By providing a standardized interface for feature access, feature stores enable data engineers to focus on building robust data pipelines while allowing data scientists to concentrate on model development and experimentation. This separation of concerns leads to more efficient workflows and better collaboration between teams. Feature stores also support feature discovery, enabling data scientists to explore and understand available features before building models. Modern implementations often integrate with data mesh architectures to enable domain-specific feature ownership while maintaining data contracts for feature quality and consistency.
Feature stores also play a crucial role in ensuring data consistency and reducing training-serving skew. Training-serving skew occurs when there are differences between the features used during model training and those used during inference, leading to degraded model performance in production. By providing a single source of truth for features, feature stores help minimize this skew and ensure that models perform consistently across different environments. Additionally, feature stores can implement feature validation and monitoring capabilities, alerting teams to potential issues with feature quality or drift. These monitoring capabilities often integrate with streaming data architectures to provide real-time feature quality metrics.
As organizations continue to scale their machine learning operations, feature stores will become increasingly important for managing the complexity of feature engineering and serving. The integration of feature stores with other components of the modern data stack, such as data lakes, data warehouses, and streaming platforms, will enable more sophisticated and efficient machine learning workflows. Furthermore, the development of standardized APIs and protocols for feature stores will promote interoperability and reduce vendor lock-in, making it easier for organizations to adopt and migrate between different feature store solutions. Consider how feature stores fit into your broader data architecture, working alongside data lakes for raw data storage, data lakehouses for unified analytics, vector databases for embedding storage, streaming architectures for real-time processing, and data mesh patterns for domain-oriented feature management.