In today's data-driven world, organizations face the challenge of managing and deriving value from both structured and unstructured data. Structured data typically resides in data warehouses, while unstructured and semi-structured data finds its place in data lakes. However, as businesses seek to leverage the full potential of their data, there is a growing need to analyze all data types using a unified set of tools and technologies. In this blog post, we will explore the concept of a data lakehouse, which aims to address the challenges associated with integrating structured and unstructured data.
Top Challenges with Data Lakes
Before I describe what a data lakehouse is, let me first detail the challenges with storing data in a data lake.
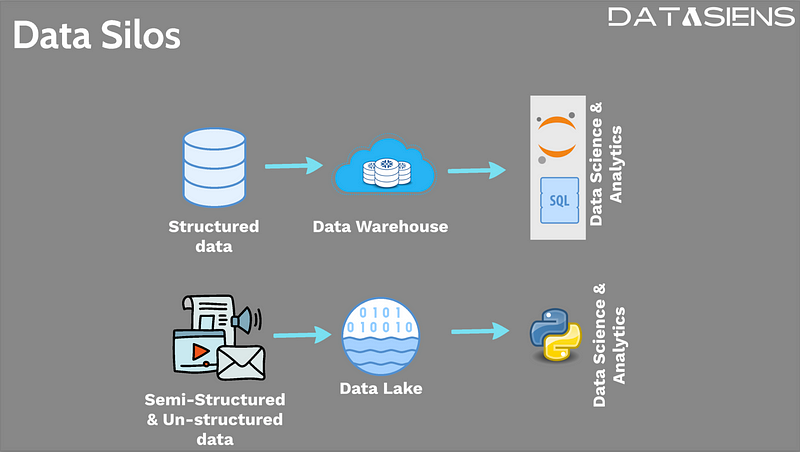
- The Problem of Data Silos
The primary issue organizations encounter when dealing with structured and unstructured data is the creation of data silos. Data analysts often work with structured data, running SQL queries, while data scientists utilize R or Python code to analyze data in the data lake. This division limits the analysts from tapping into the potential of unstructured and semi-structured data, while data scientists struggle to access valuable historical information present in structured datasets.
2. Lack of support for batch and streaming

One possible solution to overcome the data silo problem is to load structured data into the data lake alongside unstructured data. However, this approach poses several challenges. Firstly, data lakes store files in an immutable manner, meaning that modifying them in place is not possible. This limitation necessitates the creation of new files when adding or modifying rows within a dataset. While this may not be an issue for batch processing, it becomes problematic when dealing with continuously streaming data.
3. No ACID guarantees

Another challenge lies in providing asset guarantees from data transactions. The ACID principles (Atomicity, Consistency, Isolation, and Durability) ensure the integrity and reliability of data. However, data lakes do not inherently offer ACID guarantees, potentially leading to partial transactions and data corruption.
4. Lack of SQL language support for querying

Additionally, data analysts, accustomed to querying data using SQL, face obstacles when adopting the data lake as it lacks native support for SQL queries. To onboard data analysts effectively, a solution is needed to enable them to utilize the data lake and store their data seamlessly. This is where the data lakehouse concept bridges the gap between traditional data warehousing and modern data lake architectures.
Introducing the Data Lakehouse

To address these challenges, organizations can build a data lakehouse on top of the data lake. The term "data lakehouse" refers to the combination of two data management architectures: data warehouses and data lakes. By merging these architectures, users gain the ability to store and process vast amounts of data with enhanced reliability, scalability, and performance.
Key Components of a Data Lakehouse
A data lakehouse typically comprises three essential components: Delta Lake, a SQL query engine, and a data catalog.
- Delta Lake: Delta Lake, an open-source software developed by Databricks, acts as a transaction log for writes made on files stored in the data lake. Instead of directly writing to data files, writes are first logged into a transaction log. Delta Lake then updates the data files based on groups of logged transactions. This approach offers benefits such as data durability, consistency, and transactional atomicity, ensuring reliable and consistent data in large-scale data lake environments. Additionally, Delta Lake enables versioning, time travel, and the enforcement of data schemas.
- SQL Query Engine: To enable data analysts to query structured data stored in the data lake, a SQL query engine is added to the stack. This allows analysts to utilize familiar SQL language and convinces them to leverage the data lake for storing and processing structured data instead of relying solely on data warehouses.
- Data Catalog: To ensure proper visibility and management of data within the data lake, a data catalog is included. The data catalog provides a comprehensive view of the data stored in the data lake, facilitating better collaboration and data governance across the organization.
The Benefits of a Data Lakehouse
The integration of Delta Lake, a SQL query engine, and a data catalog into a data lakehouse offers several advantages. It enables the performance of merge, update, and delete operations on data files stored in the data lake. Furthermore, the data lakehouse can seamlessly handle both batch and streaming data, eliminating data silos and promoting collaboration throughout the organization. This unified approach also supports advanced analytics use cases, including vector database operations and feature store implementations.
Conclusion
As organizations seek to derive maximum value from their data, bridging the gap between structured and unstructured data becomes crucial. By building a data lakehouse on top of a data lake, organizations can overcome the challenges of data silos, immutability, asset guarantees, and query capabilities. The integration of Delta Lake, a SQL query engine, and a data catalog enables seamless storage, processing, and analysis of both structured and unstructured data. Ultimately, the data lakehouse empowers organizations to unlock the full potential of their data and make informed decisions that drive business success. For organizations implementing data mesh architectures, the data lakehouse provides the technical foundation for domain-oriented data products while maintaining data quality through contracts.
If you're interested in learning more about data architecture, I encourage you to enroll in my course on Udemy. The course covers all aspects of data architecture, including a deeper understanding of the data lakehouse.

Now that you have got a good understanding of the data types and data infrastructure, lets look at a methodology to introducing governance without compromising agility.
Click here to gain a very quick introduction to the concept of Data Mesh, its not as complicated as its made out to be.