Big data is transforming businesses — but only if you can find, understand, and effectively leverage your organization's data assets. The rise of data lakes, warehouses, and other repositories has led to organizations amassing vast troves of data. However, data often ends up fragmented in silos, with different teams owning different datasets. Accessing and making sense of relevant data becomes challenging.
Enter the "data mesh" — an emerging architectural paradigm for decentralized data management. The data mesh aims to enable self-service access to reliable, trustworthy data products. Rather than having a centralized data team control and gatekeep everything, ownership is distributed across domain teams closer to the source.
Chaos vs. Harmony
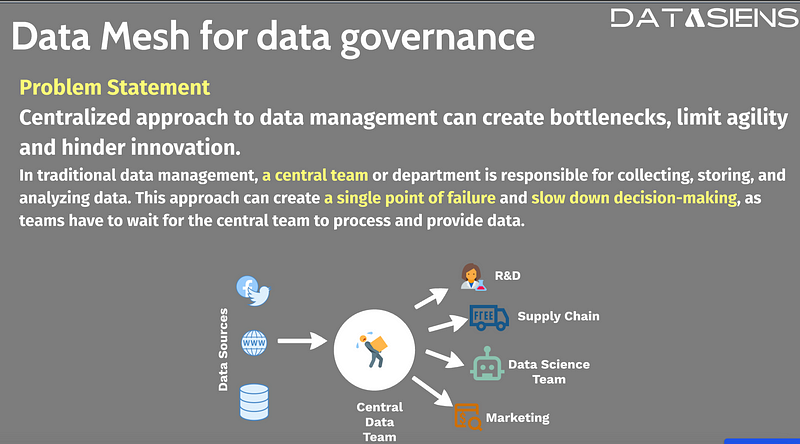
Without a data mesh, data workflows often resemble a game of telephone. The analytics team might request data from the central data team, who then has to track down the app team who generated the operational data, and so on. Bottlenecks abound, innovation lags.
The data mesh flips the script — empowering teams to own, manage, and serve up their own data products. This puts data producers and consumers in direct contact for faster, higher-quality collaboration. No more waiting around for approvals or documentation.
Four Pillars of the Data Mesh
The data mesh stands on four foundational principles:

Domain-oriented decentralization

Rather than a single centralized data team, ownership is distributed across product domains and consumer domains. This breaks down data silos and bottlenecks.
Data products mindset

Data assets are developed and managed like products — with a product owner responsible for maintaining their value and accessibility. This promotes discoverability and accountability. Modern implementations often leverage feature stores and data contracts to ensure quality.
Self-serve data infrastructure

The central data platform team provides the tools and building blocks for domain teams to assemble, manage, and serve their own data products. Access is frictionless. This often includes modern technologies like data lakehouses and vector databases for AI applications.
Federated Computational governance
Policies and standards are enforced automatically via the platform. No human gatekeeping required. This maintains integrity while keeping innovation humming. Data contracts play a crucial role in this automated governance approach.

Data Catalog Creates Harmony

A data catalog sits at the center of the data mesh, acting like a card catalog for data. Users can easily search for, understand, and request access to available data products. Descriptions, previews, and metadata offer insights into the data.
The catalog also enforces critical data governance, automatically applying tags and usage guidelines. With all data assets inventoried and governed in one place, data harmony flourishes across the enterprise. This includes managing different structured, semi-structured, and unstructured data types.
Hands on lab for experiencing the Data Catalog
If you are willing to spend 2–3 US$, I highly recommend following along the Qwicklabs on Google Data Catalog. Click on this link to enroll.
Conducting the Data Orchestra
Implementing a data mesh requires cultural change, as roles evolve from centralized gatekeepers to empowered self-service owners. But the payoff is data that flows freely across domains, underlying analytics-driven innovation and decision making. Data transforms from mess to mesh. Modern architectures often integrate streaming data architectures and data fabric approaches to create comprehensive data ecosystems.