Introduction
Step into the world of semi-structured data, where a touch of structure meets boundless possibilities. In this chapter, we explore the captivating realm of semi-structured data, where tags and markers define hierarchies and structures. From creating simple web pages with HTML to analyzing weblogs in JSON or XML formats, semi-structured data holds a pivotal role. Unlike structured data with its rigid schemas or unstructured data with no predefined format, semi-structured data offers the perfect balance. Lets uncover the intricacies of semi-structured data and its utilization in machine learning projects.
Unveiling the Nature of Semi-Structured Data
Semi-structured data offers a unique blend of structure and flexibility. Unlike traditional rows and columns found in structured data, it allows for the definition of data hierarchies using tags and markers. Take a moment to reflect on the simplicity of creating a web page with HTML, where elements are separated by tags such as `<head>`, `<title>`, and `<body>`. This form of data exemplifies the essence of semi-structured data, offering structure while enabling the freedom to define custom hierarchies.
Encounters with Semi-Structured Data
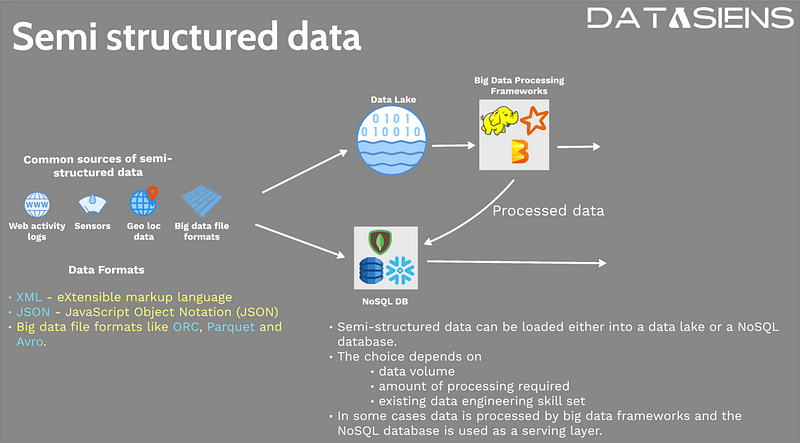
In the realm of data analysis, semi-structured data emerges in various scenarios. Analyzing weblogs, for instance, often involves working with JSON-formatted data, which stands for JavaScript Object Notation. Similarly, data from sensors is commonly produced in JSON or XML formats, where XML denotes Extensible Markup Language. Both formats leverage tags and markers to define structure, granting accessibility to readers. However, it's important to note that no two datasets will have identical structures or hierarchies, presenting a challenge for those deciphering the data. This variability makes streaming data architectures particularly valuable for real-time processing of semi-structured sensor data.
Here is an example of a JSON file that stores multiple customer records:
[
{
"name": "John Doe",
"age": 30,
"hobbies": ["coding", "reading", "hiking"],
"location": {
"city": "San Francisco",
"state": "California"
}
},
{
"name": "Jane Doe",
"age": 25,
"hobbies": ["cooking", "dancing", "traveling"],
"location": {
"city": "New York City",
"state": "New York"
}
},
{
"name": "Peter Smith",
"age": 40,
"hobbies": ["sports", "music", "movies"],
"location": {
"city": "Los Angeles",
"state": "California"
}
}
]
This JSON file stores three customer records. Each record has a name, age, hobbies, and location key-value pair. The location key-value pair is an object that stores the customer's city and state.
Processing and Storing Semi-Structured Data
The computation involved in processing and storing semi-structured data from plain text files is demanding. To overcome this challenge, specialized file formats such as ORC, Parquet, and Avro have emerged. These file formats leverage a columnar storage approach, facilitating efficient analytics and faster processing. For example, calculating the total temperature from sensor data becomes easier when the temperature column is stored in a single file. Modern data lakehouse architectures excel at handling these optimized formats while providing both the flexibility of data lakes and the performance of data warehouses.
Data Lakes and NoSQL Databases
When it comes to storing and processing semi-structured data, two popular options stand out: data lakes and NoSQL databases. Both technologies are well-suited for accommodating semi-structured data. Typically, the flow involves storing the semi-structured data in a data lake initially, leveraging big data frameworks for processing, and ultimately storing the results in a NoSQL database. This approach ensures efficient handling of large volumes of data, especially in scenarios where multiple sensors continuously generate data. For organizations implementing data mesh architectures, this pattern enables domain-specific data ownership while maintaining centralized processing capabilities.
Advantages and Challenges
Semi-structured data comes with its own set of advantages and challenges. On the positive side, it offers flexibility, making it suitable for various data types and formats. Moreover, it simplifies the process of adding new fields or attributes while retaining compatibility with existing data. On the flip side, deciphering the data structure can be challenging due to its variability. Additionally, processing semi-structured data often demands specialized tools and libraries, which can increase the complexity of data pipelines. Organizations can mitigate these challenges by implementing data contracts to ensure consistency and quality across different data sources.
Conclusion
Semi-structured data is a fascinating domain, offering the best of both structured and unstructured worlds. As the volume of data continues to grow, organizations must harness the power of semi-structured data to gain valuable insights. Whether it's analyzing sensor data, weblogs, or any other form of semi-structured data, the ability to effectively process and derive meaning from it is a valuable skill. Embrace the versatility of semi-structured data, and you'll find it to be a powerful ally in your data science journey. As you advance, consider exploring how vector databases can enhance semantic search capabilities and how feature stores can streamline your machine learning workflows with semi-structured features.